
NVIDIA® Tesla V100 is changing the game in Deep Learning, AI, HPC, Data Science, Machine Learning and Big Data Analytics – this highly advanced GPU is based on NVIDIA Volta architecture, comes in 16 and 32GB configurations, and offers the performance of up to 32 CPUs in a single GPU. Data scientists, researchers, and engineers can now spend less time optimizing memory usage and more time designing the next AI breakthrough.
Converging Deep Learning, AI and HPC Applications
Whether you are responsible for a data center or research project or marketing activities, AI is the engine we find behind consumer services we use every day, like web searches and video recommendations. AI extends traditional HPC by allowing researchers to analyze large volumes of data for rapid insights where simulation alone cannot fully predict the real world, in domains like bioinformatics, drug discovery, and highenergy physics. NVIDIA Tesla V100 is the computational engine driving the AI revolution and enabling HPC breakthroughs. For example, researchers at the University of Florida University and University of North Carolina leveraged GPU deep learning to develop ANAKIN-ME (ANI) to reproduce molecular energy surfaces at extremely high (DFT) accuracy and 1-10/millionths of the cost of current computational methods.

V100 is engineered for the convergence of AI and HPC. It offers a platform for HPC systems to excel at both computational science for scientific simulation and data science for finding insights in data. By pairing NVIDIA CUDA® cores and Tensor Cores within a unified architecture, a single server with V100 GPUs can replace hundreds of commodity CPU-only servers for both traditional HPC and AI workloads. Every researcher and engineer can now afford an AI supercomputer to tackle their most challenging work.
To connect us with the most relevant information, services, and products, hyperscale companies have started to tap into AI. However, keeping up with user demand is a daunting challenge. For example, the world’s largest hyperscale company recently estimated that they would need to double their data center capacity if every user spent just three minutes a day using their speech recognition service. V100 is engineered to provide maximum performance in existing hyperscale server racks. With AI at its core, V100 GPU delivers 47X higher inference performance than a CPU server. This giant leap in throughput and efficiency will make the scale-out of AI services practical.
Tesla V100 GPU Product Line
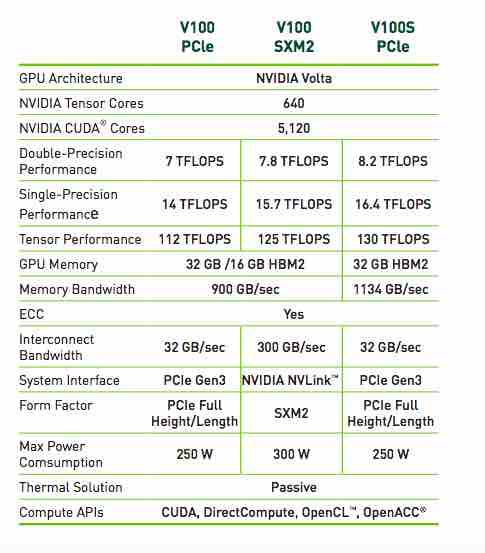
The Tesla V100 comes in 4 different forms right now based on the form-factor and performance including memory Teraflops etc. The PCI-e versions can be purchased standalone and installed in servers. The NVLInk based cards can only be bought as part of a complete system. NVLink in V100 delivers 2X higher throughput compared to the previous generation. Up to eight V100 accelerators can be interconnected at up to gigabytes per second (GB/sec) to unleash the highest application performance possible on a single server.
Tesla V100S 32GB PCI-e Card (900-2G500-0040-000)
Tesla V100 32GB PCI-e Card (900-2G500-0010-000)
Tesla V100 16GB PCI-e Card (900-2G500-0000-000)
Tesla V100 SXM2 NVLink – only available as a complete system featuring up to 8 GPUs interconnected by fast NVLink
Tesla V100 SXM3 NVLink – only available as a complete system featuring up to 16 GPUs interconnected by fast NVLink
-
NVIDIA Tesla V100S GPU 32GB PCIe 900-2G500-0040-000 for Deep Learning AI, HPC, Analytics and Research
Original price was: $10,175.00.$8,240.00Current price is: $8,240.00. -
NVIDIA Tesla V100 16GB 900-2G500-0000-000 GPU
Original price was: $8,895.00.$6,633.00Current price is: $6,633.00.

Servers & Workstations Featuring Tesla V100

Dihuni, NVIDIA and their OEM server platform providers have joined together to deliver GPU computing servers and workstations that provide double-precision performance that is both cost-effective and energy-efficient. With support for the Tesla V100, Dihuni’s GPU Computing platforms offer massively parallel compute power to solve the most computationally-intensive challenges. Dihuni offers a wide range of NVIDIA Tesla V100 servers from companies such as Dell, HPE, Supermicro, NEC, TYAN etc. These servers feature Intel Xeon or AMD EPYC processors and can be completely. custom configured. he servers are offered as barebones if you would like to build yourself or as complete Dihuni OptiReady systems configured Unlike traditional systems integrators, we work exclusively with server manufacturers to get your system built to your specifications.

Dihuni will also load your choice of Operating System and Dihuni’s Deep Learning software stack consisting of open frameworks such as Tensorflow, Caffe, Pytorch, Theano etc. These are software libraries for designing and deploying numerical computations, with a key focus on applications in machine learning. These libraries for e.g. Tensorflow allows algorithms to be described as a graph of connected operations that can be executed on various GPU-enabled platforms ranging from portable devices to desktops to high-end servers. The reason these are interesting from a NVIDIA standpoint is that some of these libraries can run up to 50% faster on the latest V100 GPUs and scale well across GPUs. Now you can train the models in hours instead of days.
Some featured products are below:
Dihuni OptiReady and Barebones Deep Learning Servers & WorkStations
For complete Tesla V100 Deep Learning servers, please visit here.

Dihuni is an NVIDIA Preferred partner. Academic/Educational and Inception Program discounts are available after pre-approval from NVIDIA.
Resources:
NVIDIA Tesla Server Compatibility
Supermicro GPU Server Compatibility
TYAN GPU Server Compatibility
NVIDIA Tesla V100 Datasheet